

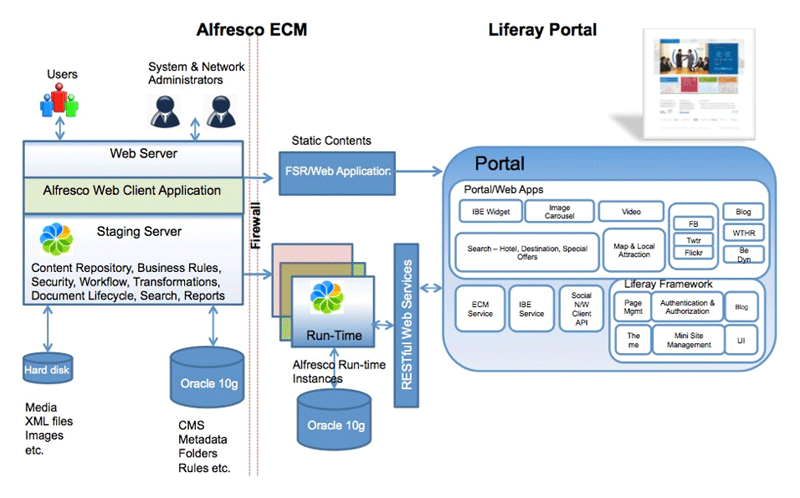
Amazon Web Services Simple Storage Service
The largest single file that can be uploaded into an Amazon S3 Bucket in a single PUT operation is 5 GB. If you want to upload large objects (> 5 GB), you will consider using multipart upload API, which allows to upload objects from 5 MB up to 5 TB.
The Multipart Upload API is designed to improve the upload experience for larger objects, which can be uploaded in parts, independently, in any order, and in parallel. The AWS tool to use to perform this is API-Level (s3api) command set.
In this tutorial, we assume:
- You have installed and configured AWS Command Line Interface on a Linux OS computer/server,
- You have an Amazon account and a S3 Bucket (MyBucketName),
- The size of the file to upload is 20 GB (MyObject.zip),
- 100 MB can be uploaded without problem using our internet connection.
Theoretically, how it works
The process involves in 4 steps:
- Separate the object into multiple parts. There are several ways to do this in Linux, ‘dd‘, ‘split‘, etc. We will use ‘dd’ in this tutorial,
- Initiate the multipart upload and receive an upload id in return (aws s3api create-multipart-upload),
- Upload each part (a contiguous portion of an object’s data) accompanied by the upload id and a part number (aws s3api upload-object),
- Finalize the upload by providing the upload id and the part number / ETag pairs for each part of the object (aws s3api complete-multipart-upload).
And practically?
1. Separate the object into multiple parts
We will create 205 parts (100 MB * 204 + 80 MB):
$ dd if=/dev/urandom of=MyObject.zip bs=1024k count=20000
$ dd if=MyObject.zip of=MyObject1.zip bs=1024k skip=0 count=100
$ dd if=MyObject.zip of=MyObject2.zip bs=1024k skip=100 count=100
$ dd if=MyObject.zip of=MyObject3.zip bs=1024k skip=200 count=100
...
$ dd if=MyObject.zip of=MyObject10.zip bs=1024k skip=900 count=100
$ dd if=MyObject.zip of=MyObject11.zip bs=1024k skip=1000 count=100
$ dd if=MyObject.zip of=MyObject12.zip bs=1024k skip=1100 count=100
...
$ dd if=MyObject.zip of=MyObject203.zip bs=1024k skip=20200 count=100
$ dd if=MyObject.zip of=MyObject204.zip bs=1024k skip=20300 count=100
$ dd if=MyObject.zip of=MyObject205.zip bs=1024k skip=20400 count=100
A one line shell script can be written to automate this process:
$ for i in {1..205}; do dd if=MyObject.zip of=MyObject"$i".zip bs=1024k skip=$[i*100 - 100] count=100; done
2. Initiate the multipart upload and receive an upload id in return
aws s3api create-multipart-upload --bucket MyBucketName --key MyObject.zip
You will received as output something like:
{
"UploadId": "UVditMTG8U--MyLongUploadId--ksmFT7N6bNTWD",
"Bucket": "MyBucketName",
"Key": "MyObject.zip"
}
3. Upload each part
For the following commands, note the console output:
{
"ETag": "\"fggcd799--ETagValue1--dhe76dd8dc\""
}
$ aws s3api upload-part --bucket MyBucketName --key MyObject.zip --upload-id \ MyLongUploadId --part-number 1 --body MyObject1.zip
$ aws s3api upload-part --bucket MyBucketName --key MyObject.zip --upload-id \ MyLongUploadId --part-number 2 --body MyObject2.zip
...
$ aws s3api upload-part --bucket MyBucketName --key MyObject.zip --upload-id \ MyLongUploadId --part-number 100 --body MyObject100.zip
...
$ aws s3api upload-part --bucket MyBucketName --key MyObject.zip --upload-id \ MyLongUploadId --part-number 204 --body MyObject204.zip
$ aws s3api upload-part --bucket MyBucketName --key MyObject.zip --upload-id \ MyLongUploadId --part-number 205 --body MyObject205.zip
Note: Once more you can write a small shell script to automate this process.
Finalize the upload
Create a JSON file MyMultiPartUpload.json containing the following:
{
"Parts": [
{
"ETag": "\"ETagValue1\"",
"PartNumber": 1
},
{
"ETag": "\"ETagValue2\"",
"PartNumber": 2
},
...
{
"ETag": "\"ETagValue100\"",
"PartNumber": 100
},
...
{
"ETag": "\"ETagValue204\"",
"PartNumber": 204
},
{
"ETag": "\"ETagValue205\"",
"PartNumber": 205
},
]
}
$ aws s3api complete-multipart-upload --bucket MyBucketName --key \
MyObject.zip --upload-id MyLongUploadId --multipart-upload MyMultiPartUpload.json
That is all, you can verify that the large file is uploaded with:
aws s3 ls s3://MyBucketName/MyObject.zip
2014-09-18 20:29:19 20495340 MyObject.zip
References and resources:
- S3 API Command Line Reference
- Amazon S3: Multipart Upload
- Introduction to Amazon S3 Multipart Upload









You must be logged in to post a comment.